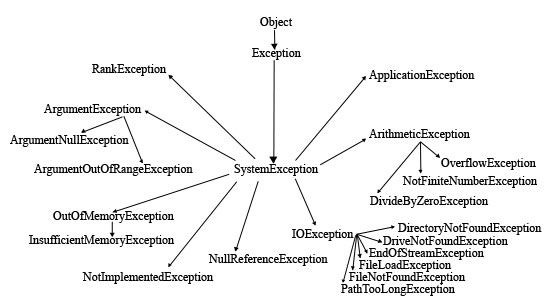
Cet article définit briévement les importantes caractéristiques des differents SGBD disponibles, Il existe bien entendu d''autres SGBD ; ici sont regroupés les SGBD sur lesquels des avis ont été donnés.
Borland
Versions
• La version IB6 (dépréciée) et Firebird OpenSource
• La Desktop Edition payante, est une version améliorée.
• La Server Edition inclut de nombreux autres outils (InterClient, IBX) ainsi qu''un support complet d''ODBC.
Avantages
• Administration aisée (auto-administrée, auto-optimisée)
• Version Opensource disponible
• Très bonne intégration aux autres outils Borland C++ Builder ou Delphi
Inconvénients
• Digère mal les grosses volumétries
• Nombre limité de connecteurs si l''on quitte l''accès via Delphi, et ceux-ci ne sont pas toujours gratuits
• Pas de cryptage
• Pas de cluster
DB2-UDBVersion actuelle : 8.2.2DB2-UDB reste de toute manière un choix d''entreprise, bien qu''une version sous Windows soit téléchargable.
Avantages
• Monitoring via le Health-center
• Nombreux assistants qui auraient dû permettre une administration plus aisée (mais très gourmande en ressources)
• Richesse fonctionnelle du language
• Gestion centralisée de plusieurs instances
Inconvénients
• Interface client Java lourd instable, peu conviviale avec des menus contextuels à rallonge. Dan les faits, seule la ligne de commandes semble stable !
• Journalisation gourmande, même avec des jounaux tournants
• Renommage de colonnes impossible = faiblesse de DDL, bien que les assistants tentent maladroitement de cacher ces faiblesses en exécutant des traitemetns lourds • Prix exhorbitant des licences
• Gestion des utilisateurs extrêmement limitative, dédiée à l''OS
• Ecriture des procédures stockées au niveau des SELECT (que l''on doit systématiquement encapsuler dans un curseur)
SQL Server, MSDE et SQL 2005 Express
Versions
• Microsoft SQL Server
• MSDE : gratuit, optimisé pour 5 utilisateurs concurrents, maximum 2 Go de disque
• SQL Server 2005 Express Edition : gratuit, limité à 1 CPU, tables de 4 Go, 32 bits unquement Les avantages et inconvénients portent sur les 3 versions citées, compte tenu que techniquement, MSDE et SQL Server 2005 Express se basent sur le noyau de Microsoft SQL Server bridé.
• Microsoft SQL Server 2005
Avantages
• Administration aisée
• Reporting disponible
• Réplication intégrée (sauf pour MSDE)
• Frontaux et assistants très poussés (sauf pour MSDE)
• Langage T-SQL très convivial, intégration de CLR
• Procédures stockées simples à écrire
• Sous-SELECT possible dans clause FROM
• Gestion de l''indexation textuelle, même si elle se relève incomplète ou inadaptée à la langue française
• Services Web
• Support XML
Inconvénients
• Mono-plateforme (MS Windows)
• Distributions fortement liées au système d''exploitation
MySQL
Versions
• MySQL Community Edition : licence GPL
• MySQL Max (sous Linux) = MySQL Community Edition + certaines options permettant l''amélioration des performances
• MySQL Pro Certified Server = MySQL Community Edition + certifié sécurité et performance + licence d''entreprise MySQL Network
• MaxDB by MySQL: anciennement connue sous le nom de SAP DB. SAP avait racheté les droits de ADABASE D à Software AG. Il l''a transféré sous licence GNU et laisse à MySQL le soins d''en continuer le développement.
Avantages
• Solution très courante en hébergement public
• Très bonne intégration dans l''environnement Apache/PHP
• OpenSource, bien que les critères de licence soient de plus en plus difficiles à supporter
• Version cluster depuis la version 4
• Facilité de déploiement et de prise en main.
• Plusieurs moteurs de stockage adaptés aux différentes problématiques.
Inconvénients
• Ne supporte qu''une faible partie des standards SQL-92
• Support incomplet des triggers et procédures stockées
• Gestion des transactions que depuis la version 4 avec InnoDB
• Assez peu de richesse fonctionnelle
• Manque de robustesse avec de fortes volumétries
• Pas d''héritage de tables
OracleVersions
• Oracle Enterprise Edition
• Oracle Standard Edition
• Oracle Personal Edition
• Oracle Database 10g Express Edition, limitée à 4 Go, 1Go de RAM, 32 bits, Linux/Windows
Avantages
• Procédures stockés en pl/sql (langage propriétaire Oracle, orienté ADA) ou ... en JAVA (depuis la 8.1.7) ce qui peut s''avérer utile pour les équipes de développement.
• Assistants performants via Oracle Manager Server, possibilité de gérer en interne des tâches et des alarmes
• Gestion centralisée de plusieurs instances
• concept unique de retour arrière (Flashback)
• Pérennité de l''éditeur : avec plus de 40% de part de marché, ce n''est pas demain qu''Oracle disparaîtra
• Réglages fins : dans la mesure ou l''on connait suffisament le moteur, presque TOUT est paramétrable.
• Accès aux données système via des vues, bien plus aisément manipulable que des procédures stockées.
• Interface utilisateur remaniée et extrêmement riche, permettant - enfin ! - le tuning fin de requêtes par modification des plans d''exécution.
• Services Web
• Support XML
Inconvénients
• Coût excessif : s''attaquant aux grosses entreprises, Oracle use de prix élevés. Il existe cependant des versions plus légères (à tous points de vue).
• Fort demandeur de ressources : ce qui n''arrange rien au point précité, Oracle est bien plus gourmand en ressource mémore que ses concurrents, ce qui implique un investissement matériel non négligeable. La connexion utilisateur nécessite par exemple près de 700 Ko/utilisateur, contre une petite centaine sur des serverus MS-SQL ou Sybase ASE .
• Porosité entre les schémas (= difficile de faire cohabiter de nombreuses applications sans devoir créer plusieurs instances)
• Métamodèle propriétaire, loin de la norme.
• Tables partitionnées, RAC... uniquement possible à l''aide de modules payants complémentaires. Parallélisme mal géré sur des tables non-partitionnées.
• Gestion des verrous mortels mal conçue (suppression d''une commande bloquante sans rollback)
• Pauvreté de l''optimiseur (ne distingue pas les pages en cache ou en disque, n''utilise pas d''index lors de tris généraux, ...)
• Pas de prise directe sur les tables système (vues système)
• Gestion erratique des rôles et privilèges (pas possible e donner des droits sur des schémas particuliers sans passer par leurs objets, désactivation des rôles lors d''exécution de packages...)
• Mais surtout: opacité de l''éditeur. Même au niveau des cours donnés par Oracle, il est quasi impossible d''obtenir des informations concernant les fonctionnements internes du moteur.










{kind=link}